How I reduced MTTR metric by 50% by uniting 4 systems into 1 incident-management platform

Tinkoff
Internal
Web
Tinkoff is one of the largest fintech companies, with over 47 million users and a rapidly growing ecosystem – both B2B and B2C.
At this scale, companies invest heavily in incident management, since service disruptions can lead to loss of customer trust, financial penalties, reputational damage and more.
Product Brief
FineDog is an incident management platform designed for SRE engineers, support teams and managers. It helps track incidents, monitor infrastructure, manage on-call schedules and much more. The goal of incident management is to detect the cause fast, fix it and minimize the impact on clients.
What are Incidents?
Incidents are those “oops” moments when something breaks and customers lose access to the company's services. Imagine if a mobile app suddenly fails to process transfers, leaving users unable to send money.

My Role
When I joined the Reliability Team as a Product Designer in 2023, there was no product yet — just strategy drafts. Since then, I’ve owned end-to-end product design and worked closely with product managers, analysts, developers and stakeholders to enhance reliability, reduce incident resolution time and improve the experience of our internal users.
Uncovering the Problem
Before I joined, the team conducted a survey on incident management, which revealed a major issue: low NPS. To understand the reasons behind this, I first analyzed how the process was structured at the time.
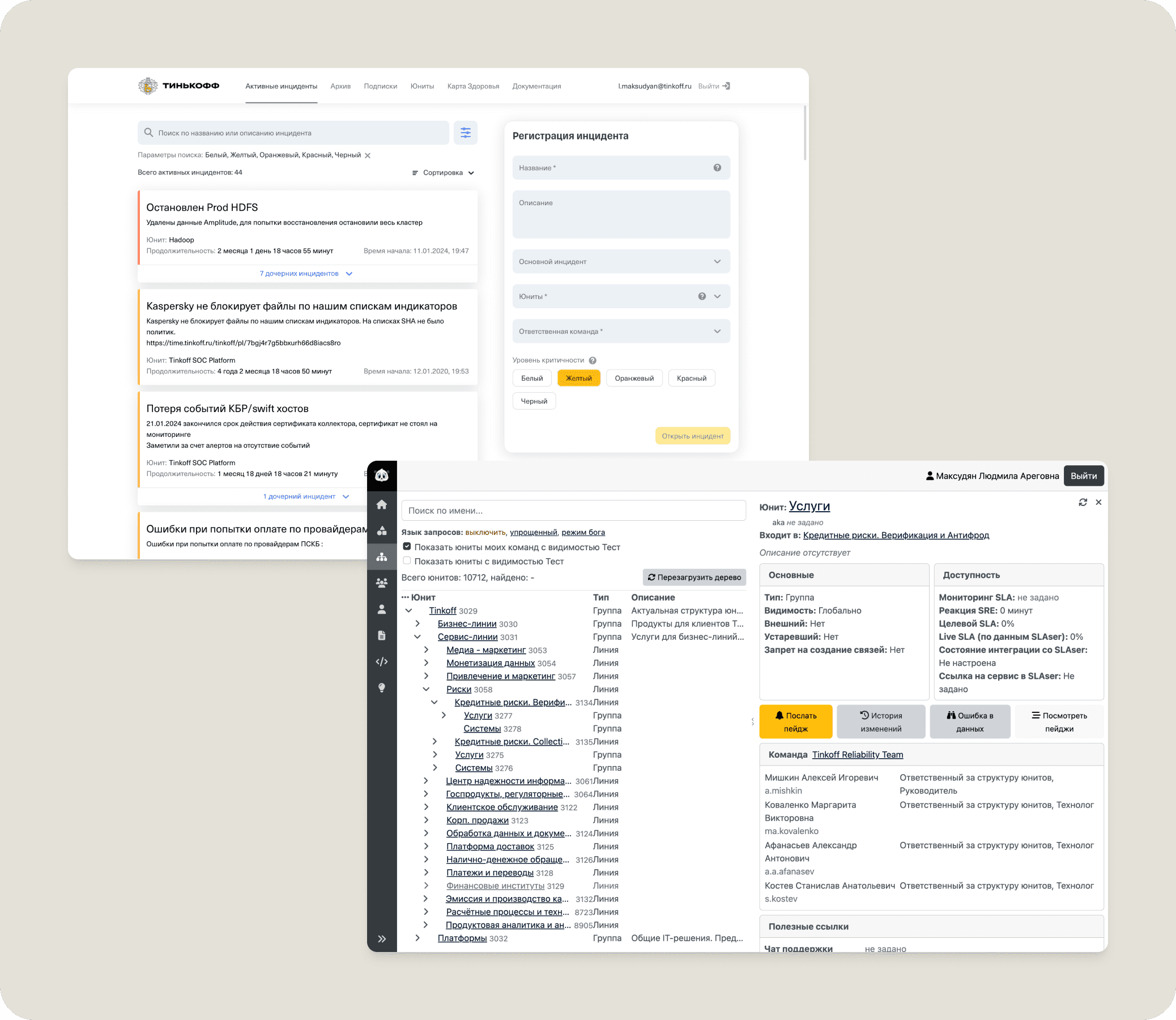
It was spread across 4 separate systems, each responsible for a specific part:
Registering and tracking incidents
Monitoring service statuses
Managing services, teams and schedules
Setting SLAs and performance metrics

Getting Insights
To gain deeper insight, I conducted 12 in-depth interviews with users to understand their workflows and pain points. It became clear that the problem wasn't just usability — it was the fragmented ecosystem itself. Users were constantly switching between tools, dealing with:
Inconsistent interfaces and patterns, making it hard to adapt and work efficiently
Fragmented workflows, slowing down incident tracking
Data inconsistencies, forcing manual transfers between platforms

After the analysis, we decided to build a single platform for all incident-management scenarios, rather than improving each system separately. Stakeholders supported this decision as it addressed key business challenges:
Reduce Resources: 4 systems were expensive and hard to maintain, while a single platform would reduce costs and improve stability
Clear Analytics: The fragmented ecosystem made it difficult to analyze reliability, while a single platform would provide clearer data
That’s how our journey of creating FineDog began.
Understanding Roles
Before jumping into design, I started by identifying the key user groups who rely on the incident management platform. Each group had different needs and workflows:

Information Architecture
To avoid simply merging old tools into one, I focused on building a clear platform architecture. I mapped out key sections and their required functionality. This also helped identify where entities would overlap and how we could create a more seamless experience.

Looking at Competitors
Although publicly available incident management tools are limited, I analyzed some of them through documentation and trial periods to identify common UX patterns and best practices, avoiding the need to reinvent the wheel.
However, most competitor solutions weren’t built for our scale. The bank’s complex service structure and large team size made them unsuitable for our needs.
Concept Development
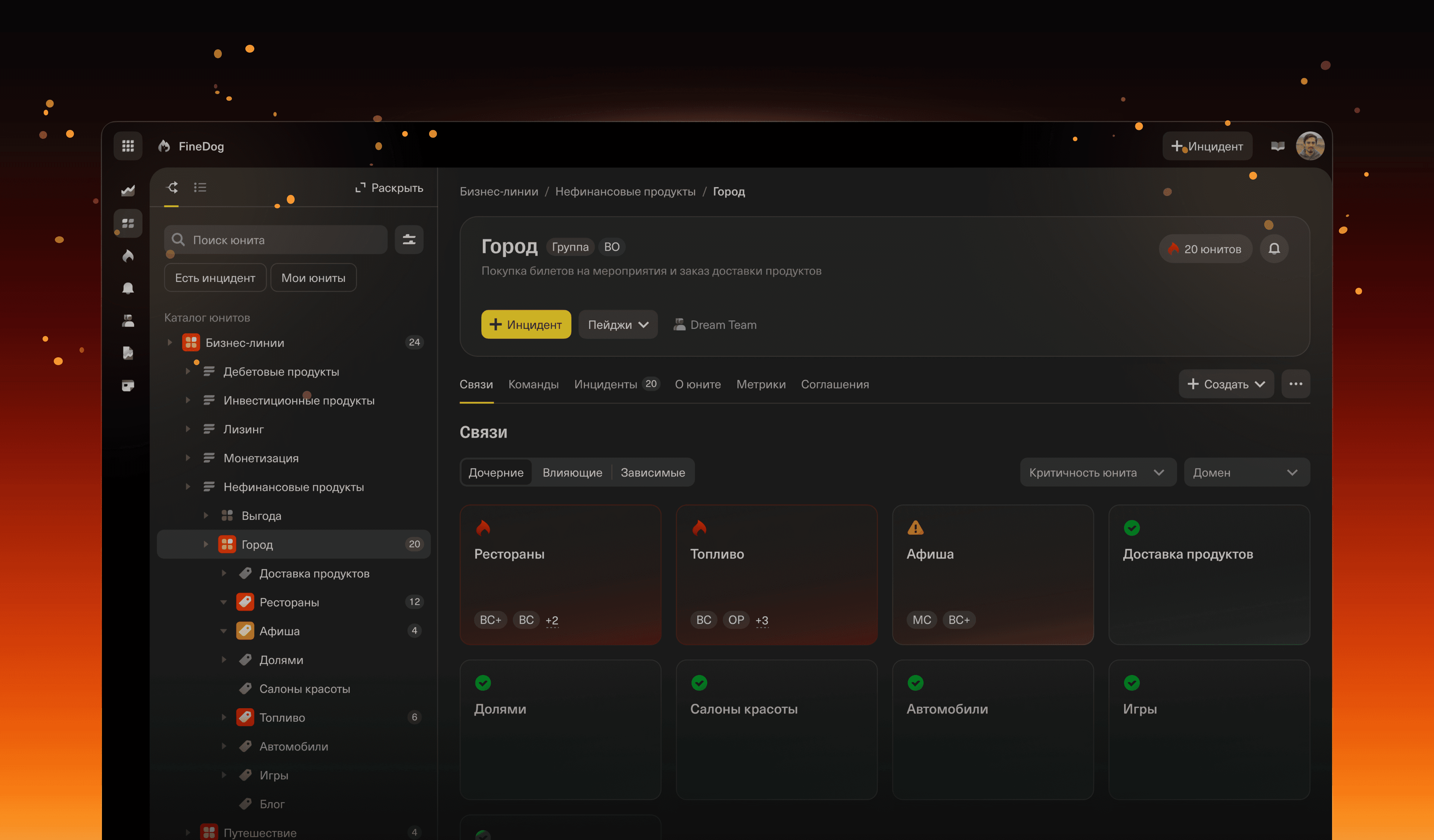
I started with the service catalog — a crucial but complex part of the platform. Information was scattered across systems, making it hard to get a clear overview. To make things clearer, I broke this part down into two main areas: сatalog structure and service details page.
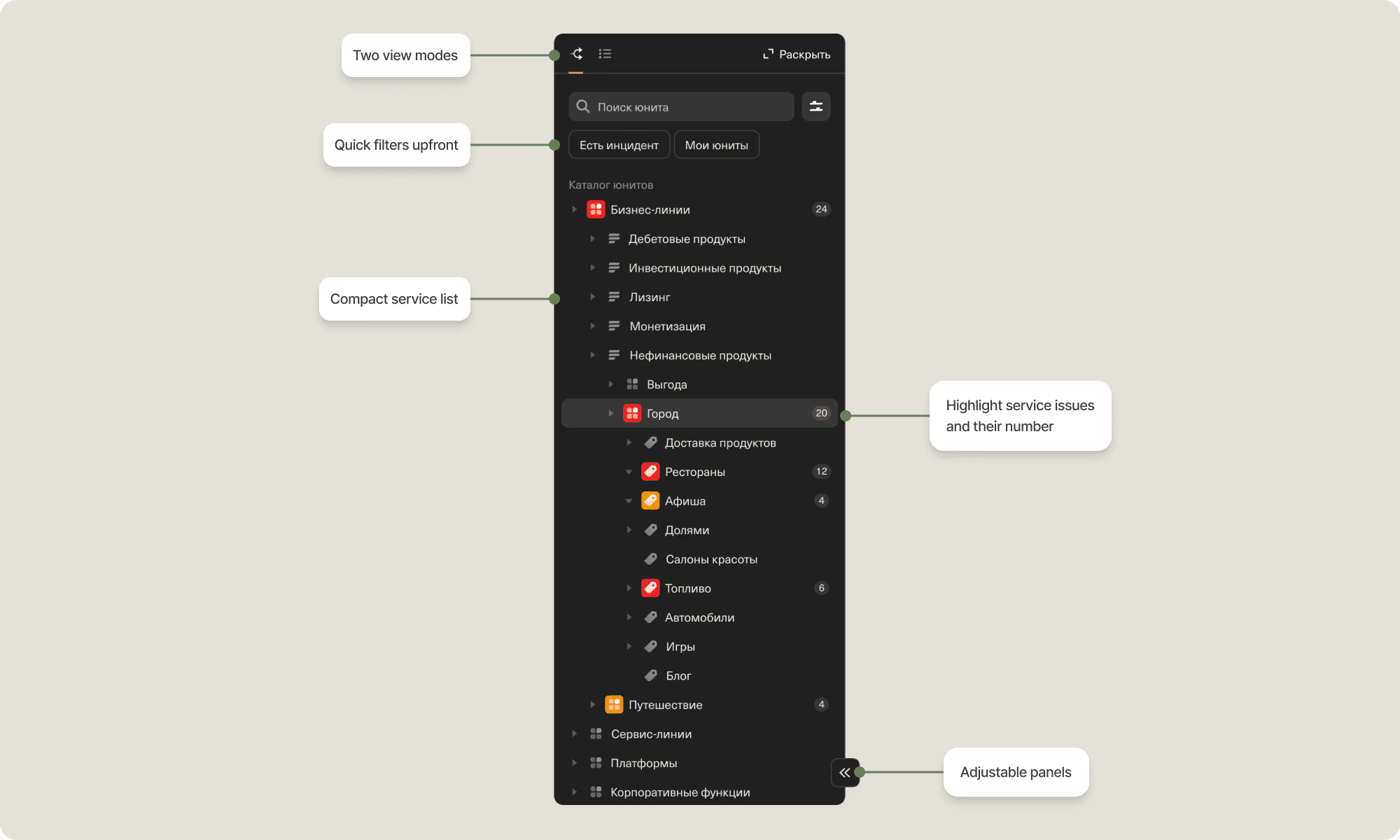
🔹 Catalog structure
The old interface was cluttered and inefficient:
Overloaded screens: Service type, description and nested services cluttered the interface.
Poor search: Only exact matches worked, making it hard to find units.
No status visibility: Users had to jump between pages to check updates.
To improve this, I introduced a compact side menu with clearer structure, replaced text-heavy unit types with icons, added status indicators, and enhanced search with filters for better efficiency.
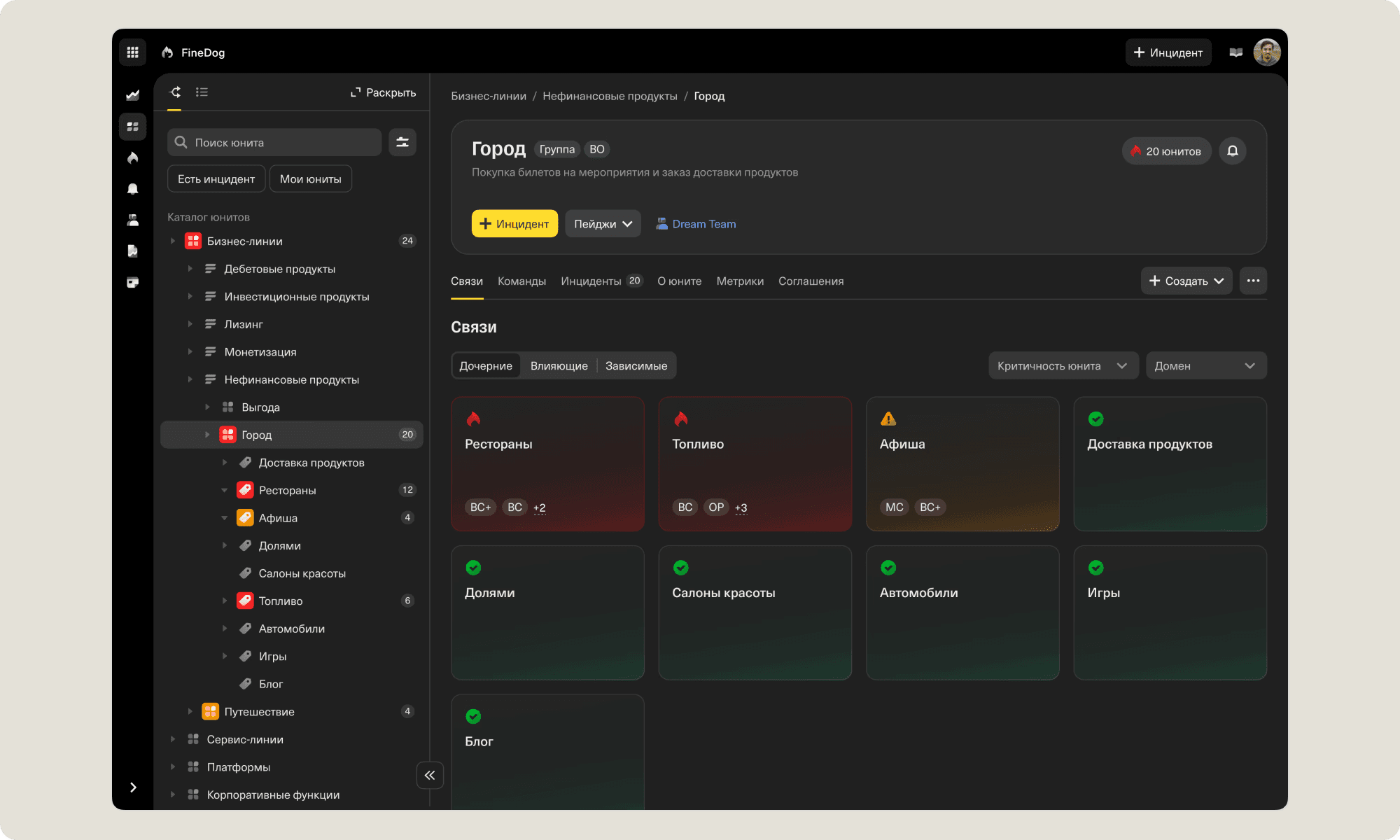
🔹 Service Details
Navigation was only part of the problem — once users reached a unit page, they often still couldn’t get the full picture. Different teams worked with the same units but for different reasons. Since the old system didn’t account for that, they had to switch between tools, pulling information from different places.

I redesigned the unit page to work as a central hub:
Displayed key data in one place: service status, responsible team, quick actions
Allowed users to switch between tabs without losing context
Made it easier to access actions (e.g. open an incident) directly from the unit page
Other Key UX Decisions
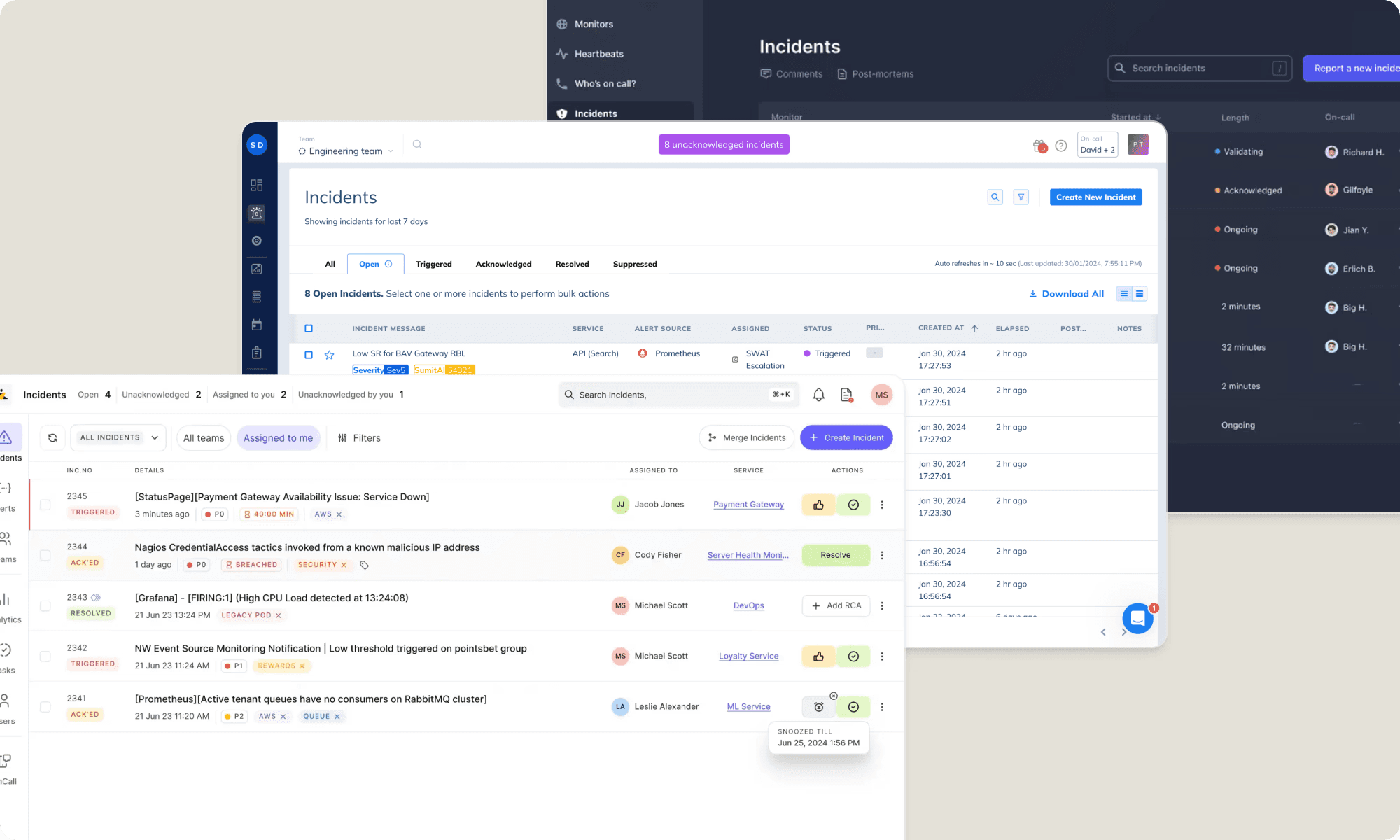
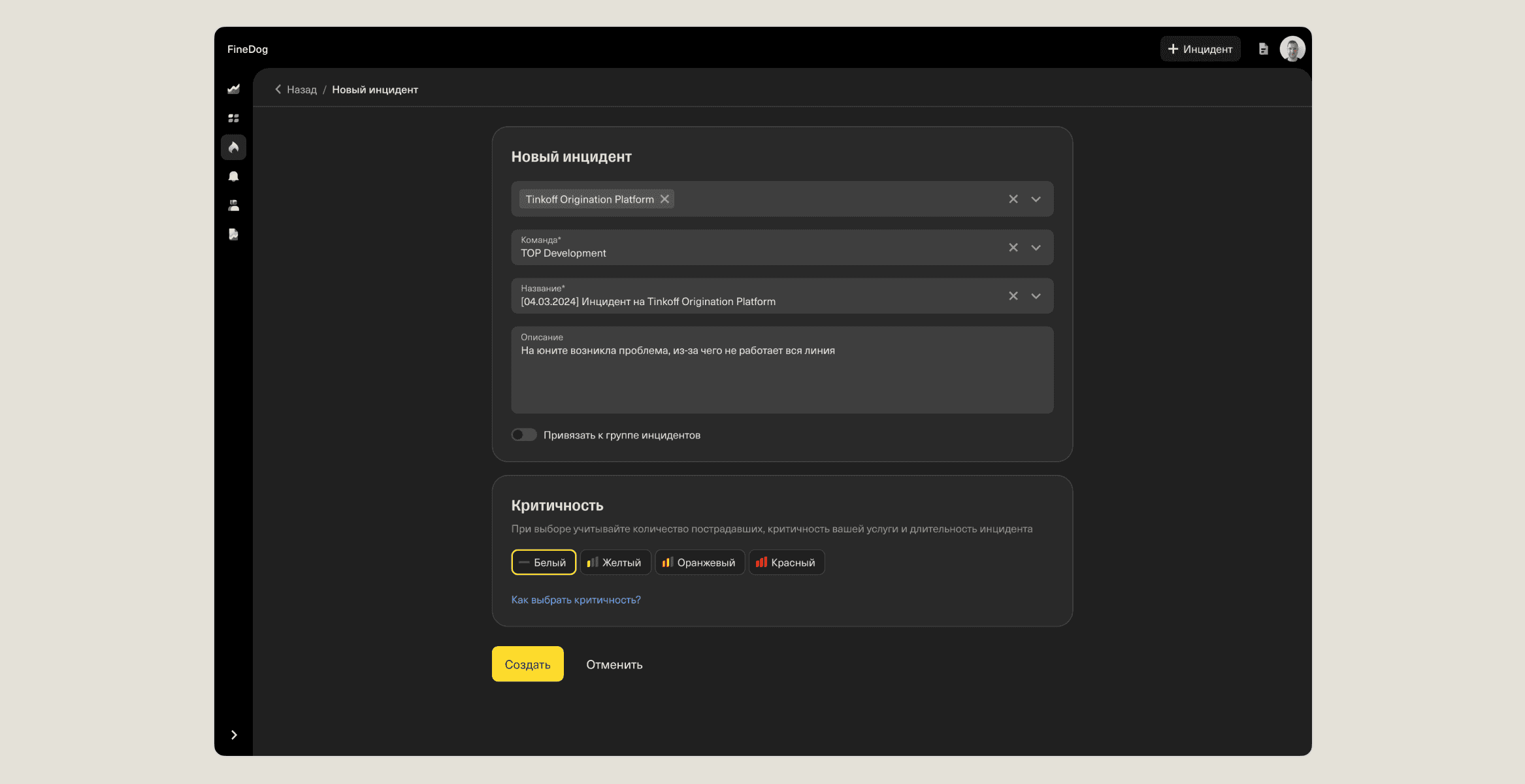
🔹 Incident Creation
I placed the "Create Incident" button in the header for quick access from anywhere in the platform. The form was kept minimal and automated: selecting a service automatically assigns a team and generates an incident name. This speeds up incident creation and improves company-wide awareness.
🔹 Incident List
I redesigned the incident cards to display more details, reducing the need to open each one. Added powerful filters and search for faster navigation. We also introduced a group incident entity to cluster related incidents caused by the same issue, making it easier to assess impact and apply bulk actions.

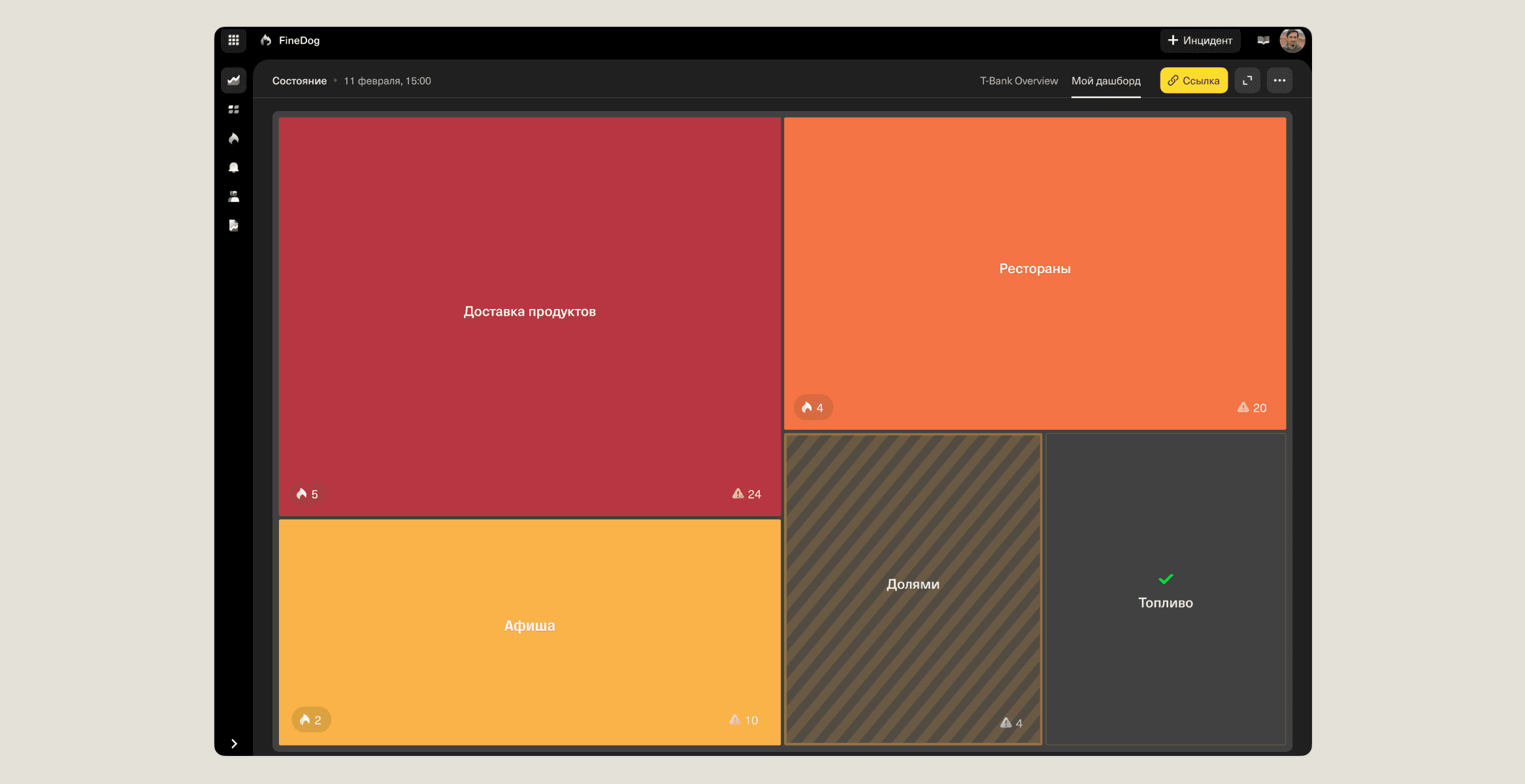
🔹Dashboards
The old status dashboard was too generic for engineers and lacked value for executives. We replaced it with two specialized dashboards, tailored to each audience. Read more about this process in a separate case study.
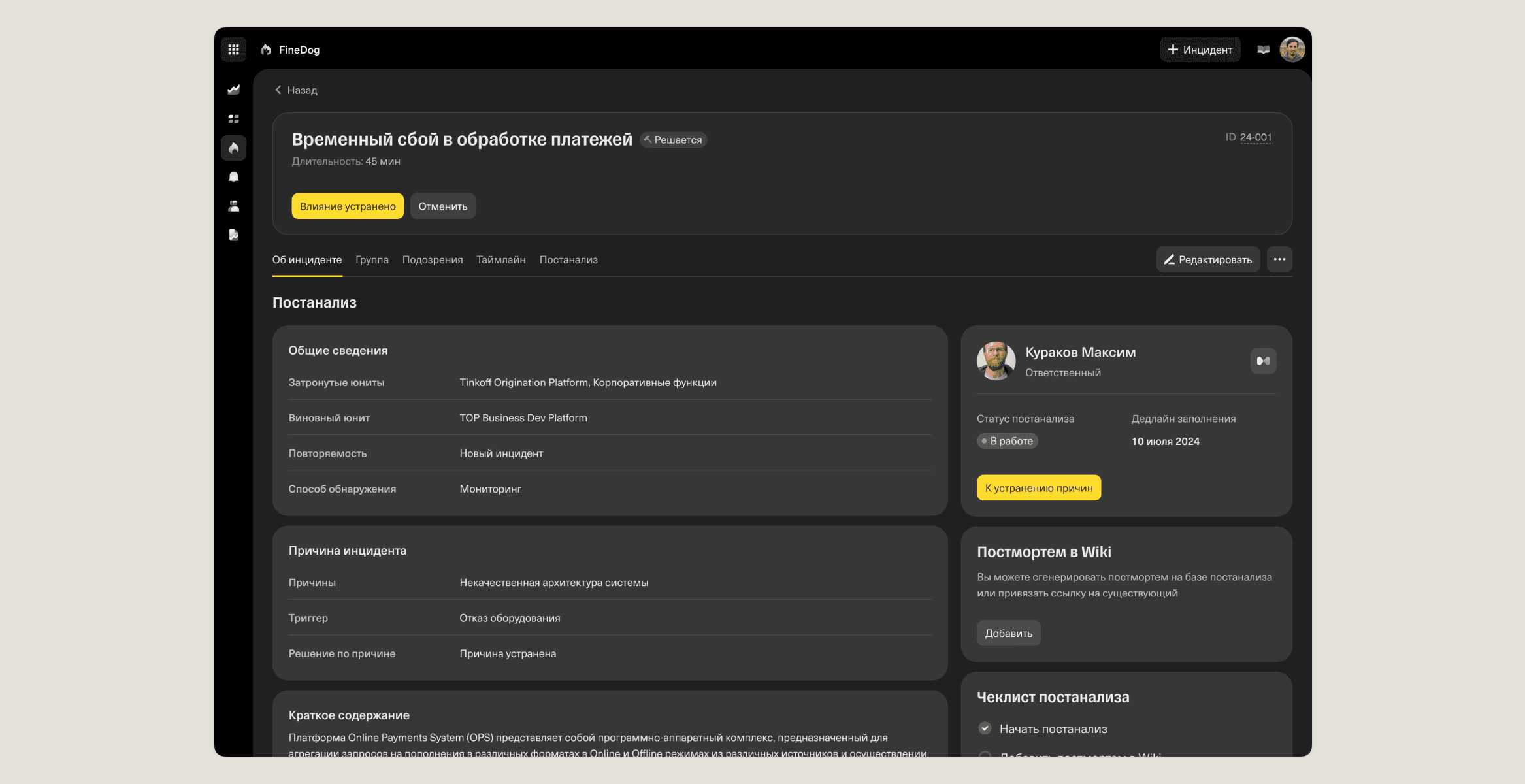
🔹Postanalysis
Before teams kept track of incident post-analysis in Confluence, where engineers copied a template, deleted extra fields and manually filled in details while switching between windows. This process was slow and inconvenient. Now, post-incident analysis is built into the incident page, with a structured form and quick answer options, making it easier to complete and track.
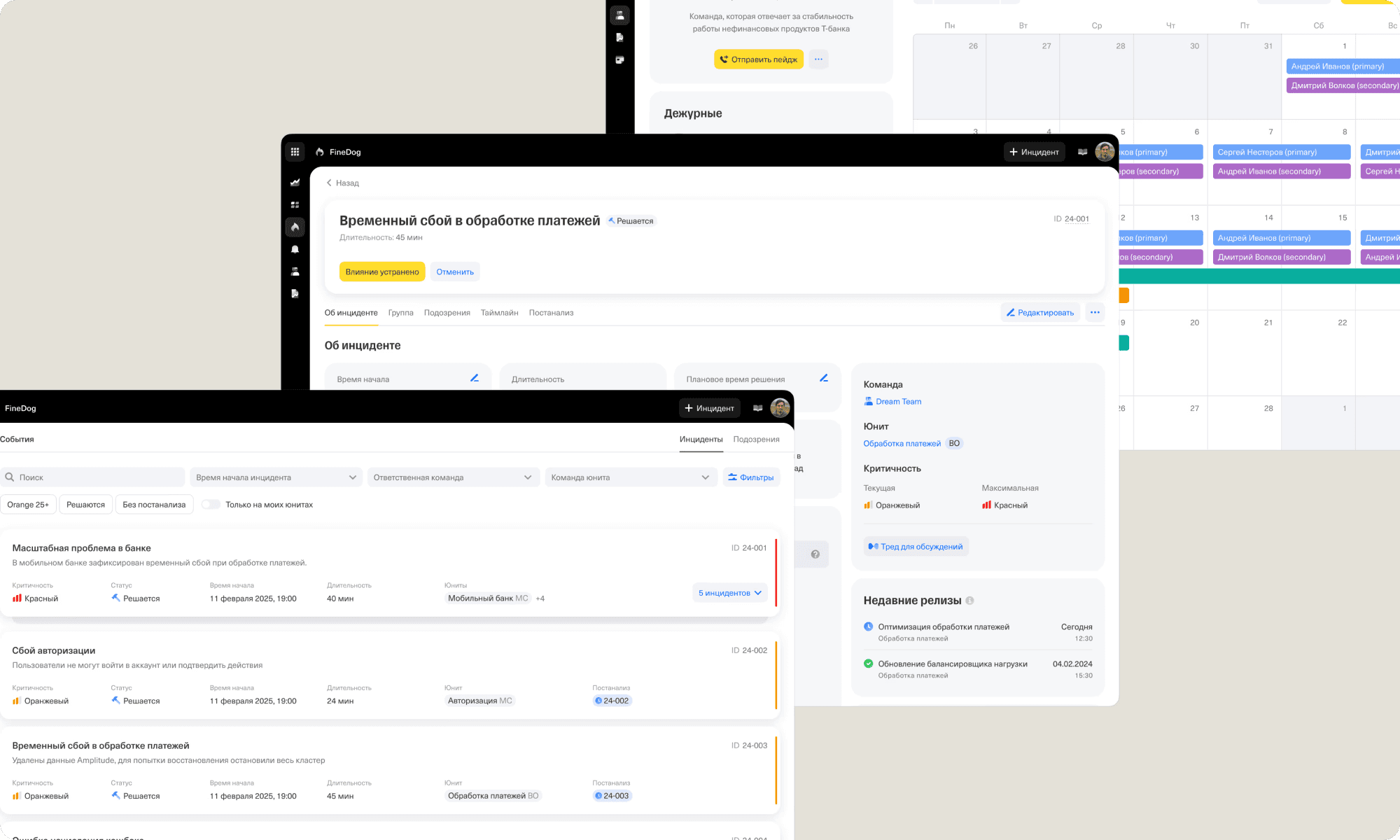
Alpha Testing
We launched the alpha test while keeping the old platforms running to ensure a smooth transition and validate our solution. 500 users joined to provide early feedback, and we actively brought in more participants through announcements, demos, and articles.
☀️ Fixing Light Mode
We launched platfrom with a dark UI, thinking it suited SRE engineers and matched a legacy tool. But many users wouldn’t fully switch without a light theme. Even though our design system supported inversion, some elements didn’t work correctly, so we had to fix them before releasing.
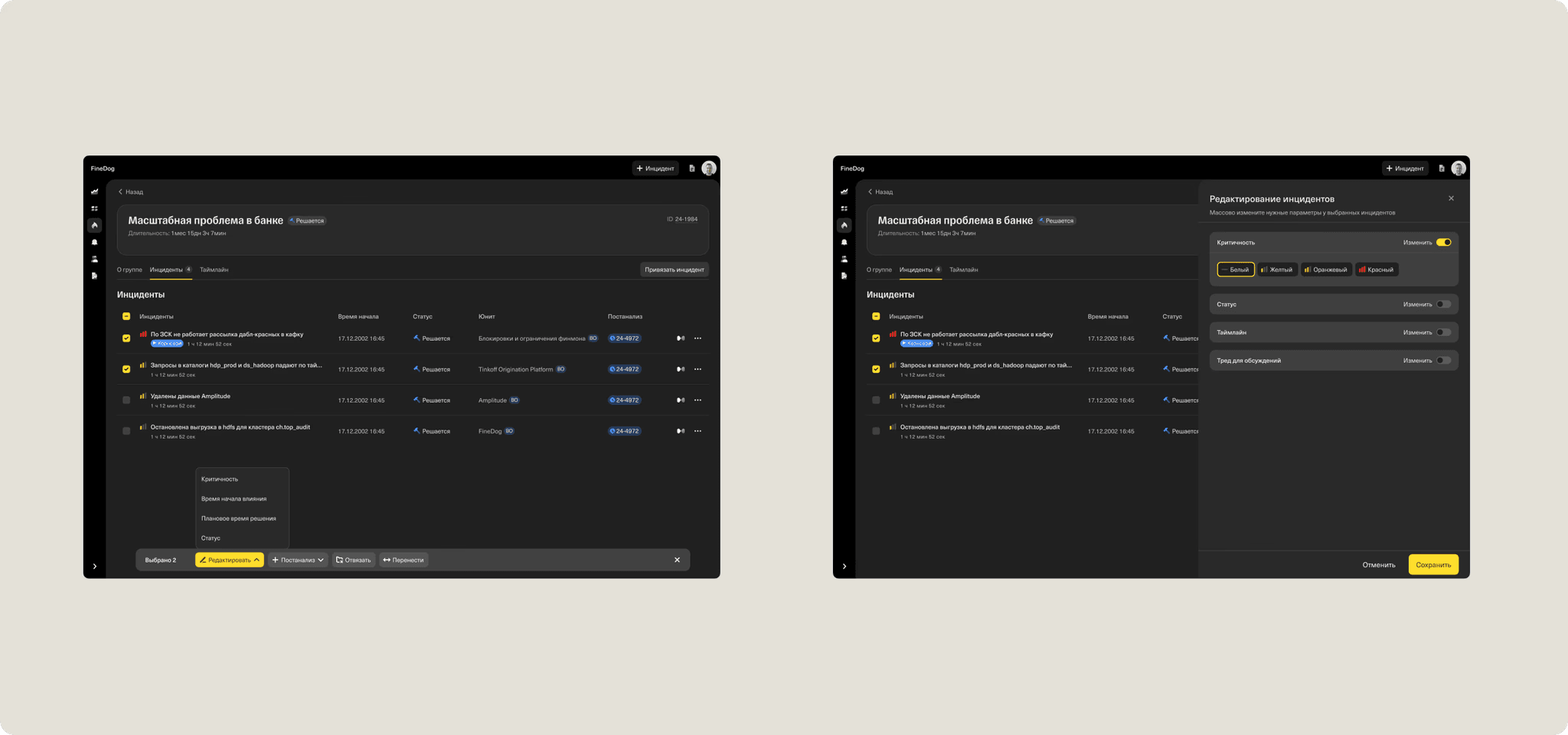
⚙️ Adding Bulk Editing
In the first version, users could only edit one parameter at a time, which turned out to be inconvenient and slowed them down. Based on feedback, we redesigned the flow to support bulk edits, making the process much faster and more efficient.
Early testers rated FineDog above 65% in CSAT across all key scenarios, confirming the platform’s effectiveness. With these strong results, we moved all users to the new system. 🚀
Outcomes
A new incident management satisfaction survey and key metrics confirmed FineDog’s success. Here are key results:

Lessons Learned
This project taught me how to balance deep involvement with trust in the team. I learned to quickly dive into new domains, rely on experts where needed, and build processes that ensured both speed and quality.